2021. 1. 19. 16:37ㆍNeural Networks/Interpretable AI
논문에 대한 오역, 의역등이 다수 포함되어 있습니다. 댓글로 많은 의견 부탁드립니다
Author : Sercan O. Arık, Tomas Pfister
Copyright © 2021, Association for the Advancement of Artificial Intelligence
TabNet은 제안과 별개로 몇가지 이슈가 존재합니다.
먼저, TabNet은 효과적인 학습을 위해 Batch Normalization을 개선한 Ghost Batch Normalization(GBN)을 도입했습니다. 하지만 virtual batch size로 입력한 크기가 batch size를 나눌 수 있는 숫자여야 한다는 제약과 별개로, 학습에 사용하는 training set도 virtual batch size로 나눌 수 있는 숫자여야 학습할 수 있다는 점을 발견하였습니다. 따라서 Tensorflow TabNet code를 사용하시는 분들은 GBN을 사용하실 때 virtual batch size가 batch size와 training set의 갯수를 동시에 나눴을 때 나머지가 0을 만족하는지 확인해보시고 학습해주세요.
또한, 논문에서 제안한 unsupervised pretrain 코드가 제공되고 있지 않습니다. 개인적으로 TabNet을 사용했을 때 virtual batch size를 제외한 나머지 hyper parameter들을 논문대로 사용했지만, 논문에 작성된 만큼의 성능을 얻지 못했습니다. 저자는 unsupervised training step이 효과적이라고 했기 때문에, encoding과정과 decoding 과정을 순차대로 거친 TabNet이 논문의 성능을 발휘하는지 확인해봐야 할 것 같습니다.(21.07.14. 수정)
저자의 Github
dreamquark-ai/tabnet
PyTorch implementation of TabNet paper : https://arxiv.org/pdf/1908.07442.pdf - dreamquark-ai/tabnet
github.com
단점으로 언급했던 많은 부분들이 수정된것 같네요. Self-supervised traininng 코드가 저자의 깃헙에 노트북 예제와 함께 게시되었습니다. 사용전 unsupervised learning으로 사전학습하시고 목적에 맞게 모델을 학습시키실 수 있습니다.
1. Introduction
Fully connected layer (FC)를 사용한 기본적인 인공신경망 deep neural networks (DNN)은 표 형태의 데이터를 일컫는 tabular dataset에서 외면되고 있습니다. 대신 ensemble method가 지배하고 있으며, 저자는 그 이유를 크게 두 가지로 구분합니다.
- Decision tree 기반의 ensemble method는 tabular data를 지배하고 있습니다. Ensemble method는 1) 테이블 데이터의 decision manifold에서 효율적이고, 2) 해석하기 쉬우며, 3) 빠르게 작동합니다.
- DNN을 구성하는 multi layer perceptron의 parameter는 과도하게 매개변수화되어있기 때문에, 테이블 형식 결정 매니 폴드에 대한 최적의 솔루션을 찾지 못하는 경우가 많습니다.
그럼에도 불구하고 NN 기반의 tabular dataset을 위한 방법이 필요한 까닭은 대규모 tabular dataset입니다. Instance 수가 많아진다면, DNN 기반 의사 결정 방법은 다른 방법들보다 좋은 성능을 보일 수도 있습니다. 동시에 표 형식 데이터를 다른 형식의 데이터와 함께 효율적으로 학습하거나, 다른 목적의 NN 학습 방법(예를 들면, 생성 모델이나 준지도학습방법)을 적용하는 end-to-end learning이 가능해집니다. 따라서, 저자들이 제안하는 TabNet은 4가지 강점을 갖는다고 소개합니다.
- TabNet은 전처리 과정이 필요하지 않습니다.
- Decision step을 통해 feature selection을 진행합니다.
- 위의 과정으로 인해 decision step별이나(local interpretability) 모델 전체의(global interpretability) feature importance를 수치화 할 수 있습니다.
- 무작위로 가려진 feature 값을 예측하는 unsupervised pretrain 단계를 적용하여 상당한 성능 향상을 보여줍니다.
2. Related work

위 그림은 FC와 mask, activation function을 조합하여 만든 DNN 블럭이 DT처럼 의사 결정을 수행할 수 있다는 것을 보여줍니다. Tabular dataset의 두 변수 $x_1, x_2$가 위 그림과 같은 sparse matrix Mask를 통과하게 되면 특정 변수를 선택한 것과 같은 효과를 얻을 수 있습니다. 선택된 특정 변수만으로 FC와 activation function을 조합하여 의미를 추출할 수 있겠죠. 기존의 DNN은 FC를 통과할 때 perceptron처럼 feature로부터 weight를 전달받았다는 점을 고려하면 큰 차이로 보입니다. 또한 변수선택된 이후 의미 추출 과정에서 해당 변수 외 다른 변수들이 개입하지 않기 때문에 ReLU를 통과한 output들은 서로 상호 독립적입니다. 동시에 output들은 오로지 가중치 $C_k$에 의해 의미의 격차를 부여받습니다. Output들의 의견을 합쳐 의사 결정에 사용한다면 DT구조를 갖는 DNN 모델을 생성할 수 있습니다.
3. TabNet - architecture

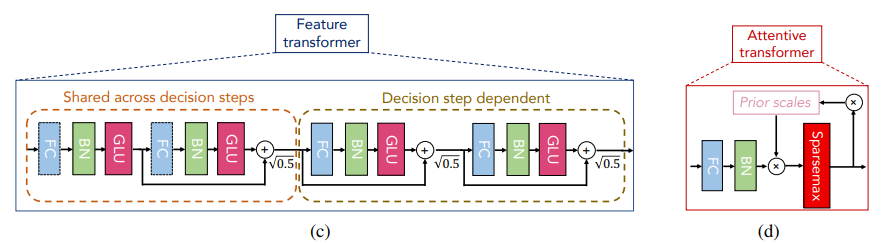
Related work에서 제안한 이상적인 구조를 만족시키기 위해 Tabnet은 위의 구조를 채택합니다. Feature transformer는 Fully Connected Layer (FC) - Batch Normalization (BN) - Gated Linear Unit Activation (GLU)로 구성된 블럭들을 순차적으로 통과하는 구조를 쌓고, 블럭간의 residual skip connecion을 적용했습니다. 그리고 residual output의 normalization을 위해 $sqrt(0.5)$를 곱했다고 하네요. 왼쪽 두개의 블럭은 decision step에 상관없이 공유하면서 사용되지만(Shared across decision steps), 오른쪽 두 블럭은 Step마다 별도의 블럭을 사용하여(Decision step dependent) step 별 독립적인 의미 추론을 가능하도록 고안했습니다. 또한 GLU를 통과하면 activation 과정 중 hidden tensor size가 반으로 줄어들게됩니다. 따라서 모든 FC들은 feature transformer의 2배가 되는 hidden tensor를 출력합니다.
이어서 D개의 변수를 갖는 값들을 입력받은 feature transformer는 split할 값들을 내보냅니다. 총 $(B,N)$의 output을 내보냈을 때, 논문에서는 split 과정을 통해 $d[i]$와 $a[i]$로 나눴습니다. 그리고 나뉜 두 tensor의 크기는 $(B,N_d),(B,N_a)$이며 $N=N_d+N_a$를 만족해야 합니다. 서로 다른 크기를 가질 수 있지만 논문에서는 대부분 $N_d=N_a$로 사용했습니다. 나뉜 $d[i]$는 output을 위해 사용되며, ReLU activation을 거치게 됩니다. 그리고 $a[i]$는 trainable mask의 학습을 위해 사용됩니다.
Attentive transformer는 $a[i-1]$을 입력받고 D개의 크기를 갖는 sparse matrix $M[i]$를 출력합니다. FC와 BN을 사용해 D개의 hidden size로 변환하며, trainability를 부여하고, prior scale $P[i]$을 곱하여 제약을 만든 후, sparsemax activation으로 feature selection하는 trainable mask를 생성합니다. Sparsemax는 softmax보다 sparsity를 강조하도록 제안된 activation입니다. 때문에 극단적인 feature selection효과를 얻을 수 있게 되고, Sparse matrix와 변수들을 element-wise하면 특정 변수만 선택한 효과를 얻을 수 있습니다. 또한 attentive transformer는 DNN 블럭으로 이뤄져있어 학습이 가능하기 때문에, 사람이 개입하지 않은 feature selection을 진행할 수 있습니다.
4. TabNet - detail
Prior scale $P[i]$의 초기값 $P[0]$는 supervised learning에서는 $1^{B,D}$로, unsupervised learning에서는 $0^{B,D}$로 제안되었습니다. Prior는 step $i$가 진행될수록 아래와 같습니다.
$$P[i]=\prod_{j=1}^{i} (\gamma-M[j])$$
$\gamma$는 relaxation parameter라고 하며, 한번 선택된 feature가 다시 사용될 여지를 부여하는 hyper parameter입니다. 위 수식을 생각해보면 간단합니다. $M[i]$는 D개의 feature 중 하나를 선택하기 때문에, 어떤 한 차원은 1로, 나머지는 0을 갖습니다. 이 값을 relaxation parameter $\gamma=1$로부터 빼게 되면 선택된 값은 0, 나머지는 1이 됩니다. 그리고 attentive transformer의 과정 중 prior scale $P[i]$가 반드시 곱해지기 때문에 한번 선택된 feature는 더이상 반복해서 선택될 일이 없게 됩니다. 만약 $\gamma>1$이라면 다시 한번 뽑힐 가능성도 생기지만 sparsemax activation을 생각하면 매우 낮은 확률이겠죠. 그럼에도 불구하고 뽑힐 여지를 주었을때 실제로 유용한 feature라면 뽑힐 수 도 있을 것 같네요.
이제 $d[i]$를 모아 aggregating하면, output을 위한 embedding tensor를 생성할 수 있습니다. Related work에 소개된 대로, 정말 feature들을 독립적으로 뽑았다면, 해당 feature로부터 추출한 hidden variables는 덧셈만으로도 충분한 의미를 갖게 됩니다. 그리고 분류, 회귀를 위한 output shape, objective, loss function을 고려해준다면 충분히 학습시킬 수 있습니다. 그런데 다시 생각해보니 prior가 뽑히는 의미를 강제하는 제약이 빠져있네요. 저자는 제약조건을 충족시키기 위해 regularization term $L_{sparse}$을 도입합니다. 그리고 그 식은 아래와 같습니다.
$$ L_{sparse} = \sum_{i=1}^{N_{steps}} \sum_{b=1}^B \sum_{j=1}^D {-M_{b,j}[i]\log{(M_{b,j}[i]+\epsilon)} \over N_{steps} \cdot B} $$
위 식에서 $N_{steps}, B$ 부분은 $\sum$과 함께 평균으로 간주할 수 있습니다. 평균인 부분을 제외하면 Mask 별 entropy의 합과 같네요. Entropy는 0.5일 때 최댓값을 갖기 때문에 mask $M[i]$ 별 확률값이 0 또는 1로 강제되게 되고, 결론적으로 sparsity를 강조시키게 됩니다.
마지막으로 뽑힌 feature의 의미를 확인하는 일만 남았습니다. Mask에 의해 feature가 뽑혔기 때문에, mask를 평가하는 것은 model의 feature selection을 확인할 수 있습니다. 그리고 mask와 동시에 의사 결정에 사용된 $d[i]$에 대해서도 고려했을 때, 적절한 feature selection 결과를 확인할 수 있습니다. 해당 결과를 위해 필요한 수식은 아래와 같습니다
$$\eta_b[i]=\sum_{c=1}^{N_d} ReLU(d_{b,c}[i])$$
$$M_{agg-b,j}={ \sum_{i=1}^{N_{steps}} \eta_b[i]M_{b,j}[i] \over \sum_{j=1}^D \sum_{i=1}^{N_{steps}} \eta_b[i]M_{b,j}[i] } $$
분모는 분자부분에 대한 scaling factor입니다. 그리고 분모는 decision output과 mask의 element wise한 결과물이네요. 결국 선택된 feature가 얼마나 큰 가중치를 받았는지 확인하는 과정입니다. 그리고 related work에서 보여드린 그림과 같이 표현할 수 있게 되었습니다.
5. Results
논문에서는 꽤 다양한 실제 dataset 및 Kaggle에서 제공한 회귀 dataset으로 평가를 시도하였습니다. 논문대로 결과를 얻을 수 있다면 TabNet은 ensemble기법만큼 강력한 NN기반 의사 결정 모델이라고 할 수 있을 것 같습니다. 논문에 실린 결과는 상단 링크를 참고해주세요.
'Neural Networks > Interpretable AI' 카테고리의 다른 글
| Accurate Intelligible Models with Pairwise Interactions (2013) (1) | 2022.12.23 |
|---|---|
| Neural Additive Models: Interpretable Machine Learning with Neural Nets (0) | 2022.03.01 |